This project suggests a hardware design for accelerating DNN (Deep Neural Networks) inference.
This design is based on a new approach for a specialized architecture, in which memory units and computation units packed together to form basic block called a Tile.
Most modern processors (and GPUs aren’t different from that prospective) called Von-Neumann architectures. In their most basic principles lays the following idea: each mathematical operation can break into multiple serial atomic operation. Then the processor can perform its task as a series of load from memory – do some atomic operation – store to memory again.
This approach works well for most workloads, but works poorly on massive parallel workloads, such as matrix multiplication – a fundamental part of every DNN.
Therefore, the communication with the memory became major bottleneck while trying to improve processor performance on DNN workloads.
In this work, we suggest to break the main memory into relative small independent memory units. Each unit related to specific tile.
Instead of one large main memory, each tile keep its weights close to calculation unit.
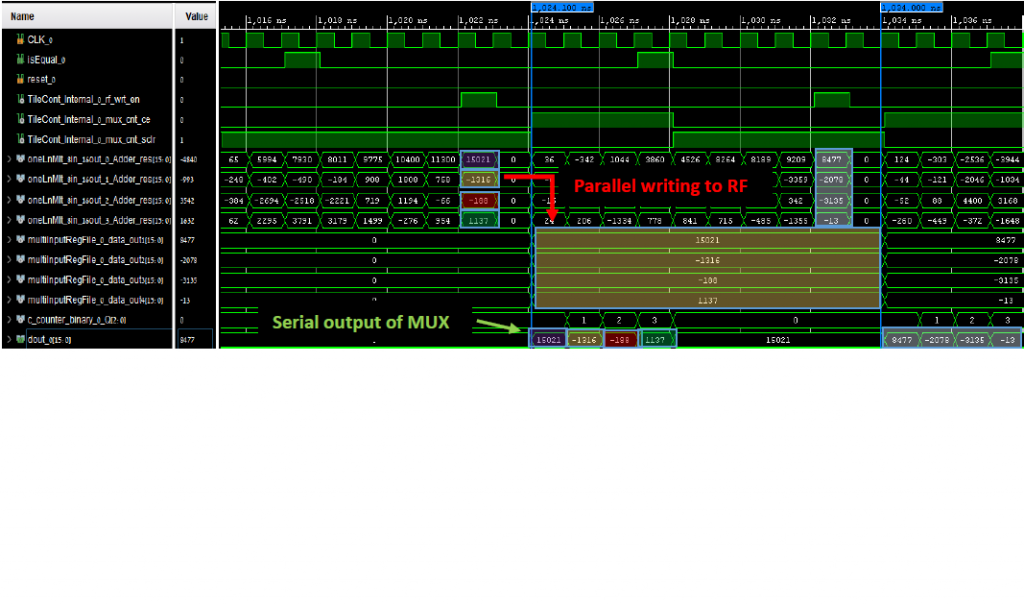
In order to achieve parallelism in Tile resolution, a new ordering method for the weights in each tile presented. Matrix multiplication by vector is in fact many independent multiplications and accumulations. One can “Accelerate” memory accesses by reading multiple values in a single read (see section ‘4.2.1 Re-Ordering the Weights’ for more’).
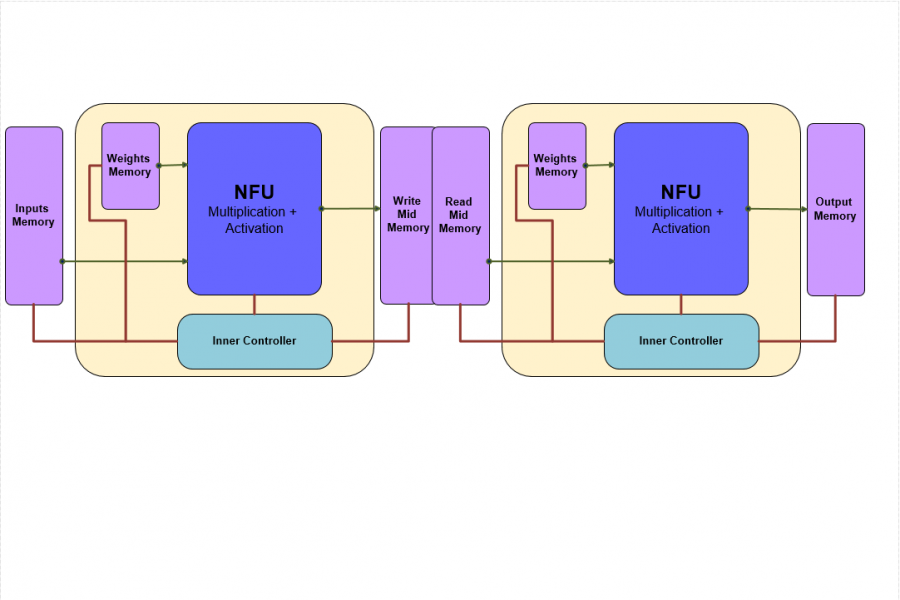
The main part of the solution is the Tile. A Tile is a generic unit which contains one NFU (neural functional unit), a relatively small memory for weights and simple controller. Multiple tile can be concatenated to create a network. A network is basically a flow of data from tile to the next, in each it changes, the same way it does in deep neural network. Between each tile there are more memories, to hold the inputs during calculation, and aggregate the intermediate outputs. In that way, multiple tile can work together at the same time, achieving relatively high throughput and utility.
The network is implemented on programmable logic side of the FPGA. The control and data come from Processor side via axi4lite interconnect.