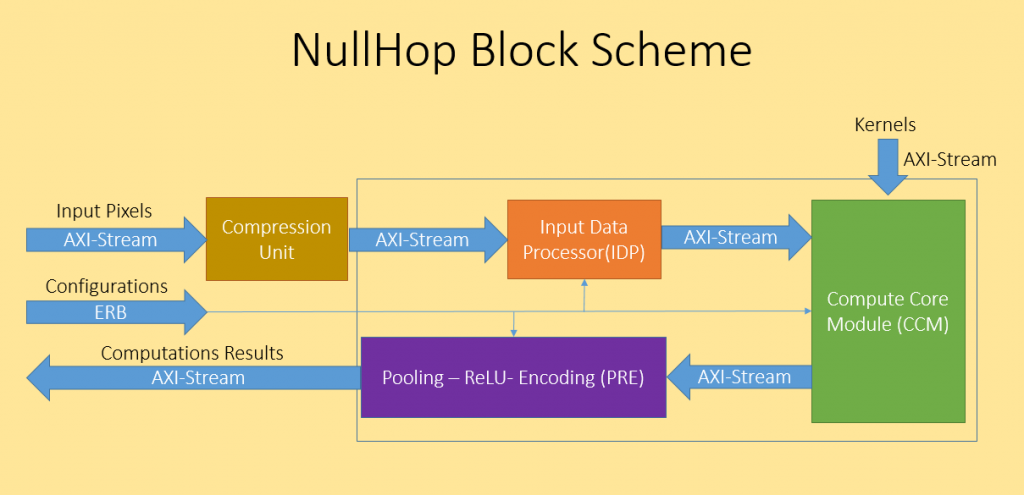
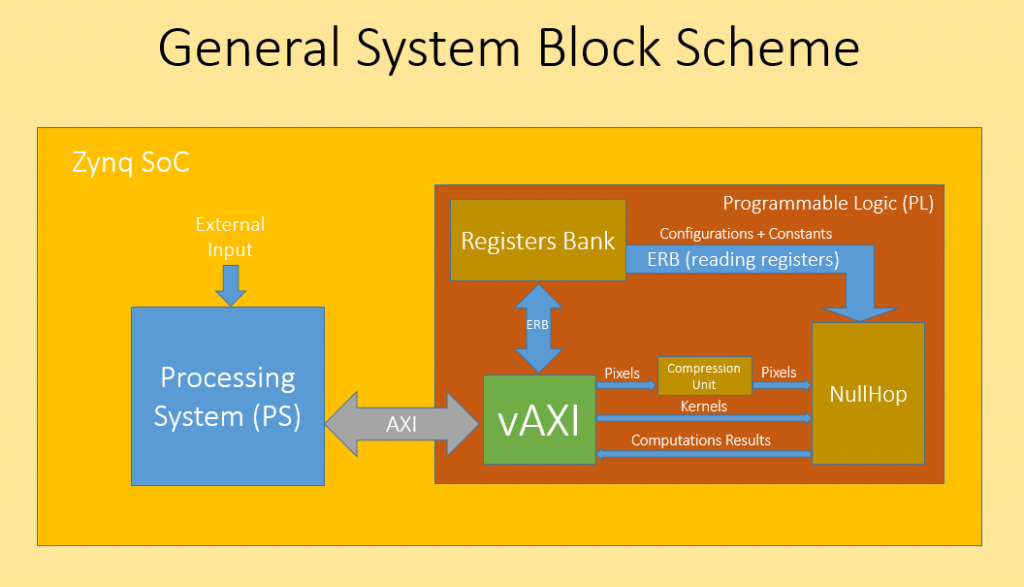
In this project, which is mostly based on an article named "NullHop", one unit of a dedicated architecture for running Convolutional neural networks (CNNs) was implemented in RTL.
This architecture is expected to achieve significantly improved performance than running CNNs on GPU.
This unit (“Compression Unit”) greatly reduces the total number of operations required to run CNNs.
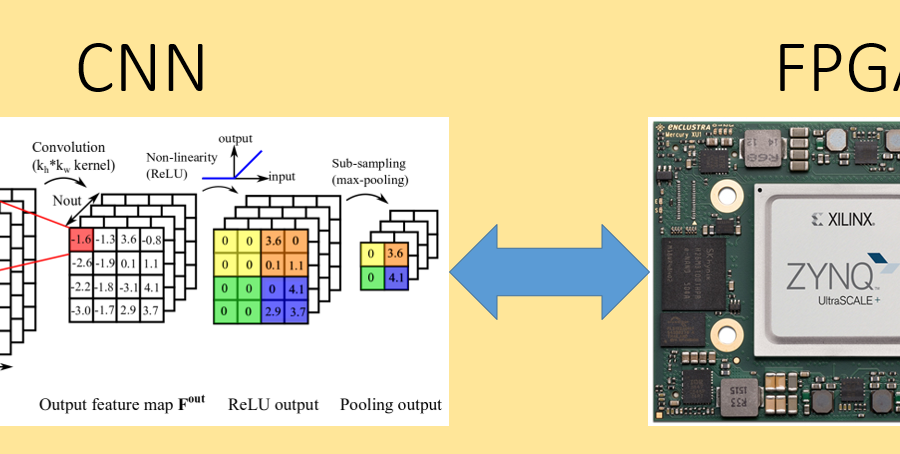
Convolutional neural networks (CNNs) have become the dominant neural network architecture for solving many state-of-the-art visual processing tasks.
Even though Graphical Processing Units (GPUs) are most often used in training and deploying CNNs, their power efficiency is less than 10 operations per second for single-frame runtime inference.
Therefore, we can expect that hardware implementation of a dedicated architecture for running CNNs may achieve better performance compared to running CNNs on generic GPU, in terms of power efficiency and runtime speed.
In this project, which is mostly based on an article named “NullHop”, one unit of a dedicated architecture for running CNNs was implemented in RTL. This architecture is expected to achieve significantly improved performance than running CNNs on GPU. This unit (“Compression Unit”) greatly reduces the total number of operations required to run CNNs.